Learner's Notes: Linux membarrier() System Call - Details of Asymmetric Fences
Asymmetric Fences?
While browsing through Folly’s synchronization primitives to study up on concurrency concepts, one familiar-looking name in the codebase caught my attention: Asymmetric Thread Fence. I already knew what std::atomic_thread_fence is meant to achieve, but what does this construct do? And what exactly is asymmetric about it?
That question led me down an interesting rabbit hole: understanding the details of asymmetric thread fences and what they are actually doing underneath the hood (at least on Linux). We’ll start with the C++ proposal for this construct, then work our way down into the implementation details.
C++ P1202R0 Introduction
We’ll walk through the mechanics in a later section, but for now it suffices to understand what these fences are trying to achieve. Referring to the proposal, let’s look at the overview:
Some types of concurrent algorithms can be split into a common path and an uncommon path, both of which require fences (or other operations with non-relaxed memory orders) for correctness. On many platforms, it’s possible to speed up the common path by adding an even stronger fence type (stronger than
memory_order_seq_cst) down the uncommon path. These facilities are being used in an increasing number of concurrency libraries. We propose standardizing these asymmetric fences, and incorporating them into the memory model.
Essentially, a concurrent algorithm may originally require a fence on both sides. However, if one path is significantly more common than the other, we may optimize for the common path by using a lighter fence there, while shifting the heavier synchronization cost onto the uncommon path. This can result in an overall performance improvement if we ensure the performance gain from the common path is much more than the overhead from the heavier fence of the uncommon path.
This pattern is more common than it may first appear. If you browse through Folly’s codebase, you can find several uses of it:
folly/synchronization/HazptrDomain.h: Hazard Pointersfolly/synchronization/detail/ThreadCachedReaders.h: RCUfolly/executors/ThreadPoolExecutor.cpp: Thread Pool ExWcutor
Let’s begin with a modified example from the paper, known as Dekker’s example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
atomic_int x{0}, y{0};
int r1, r2;
// Path A:
x.store(1, memory_order_relaxed);
atomic_thread_fence(memory_order_seq_cst);
r1 = y.load(memory_order_relaxed);
// Path B:
y.store(1, memory_order_relaxed);
atomic_thread_fence(memory_order_seq_cst);
r2 = x.load(memory_order_relaxed);
// Happens after both paths are completed.
assert(!(r1 == 0 && r2 == 0)); // Never fails.
We know the assertion cannot fail. Let’s examine why under the C++ memory model: 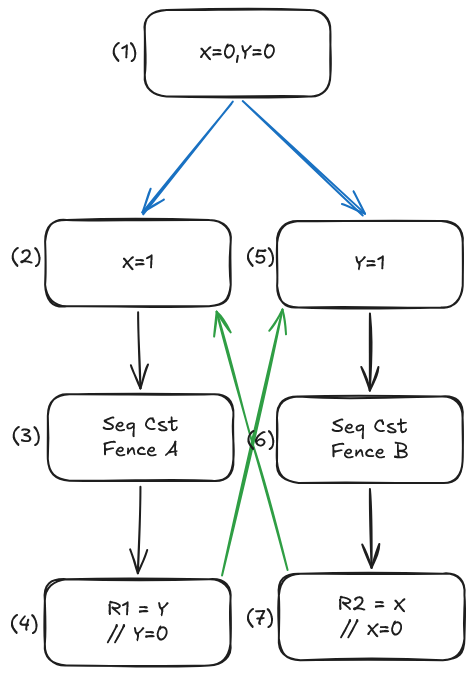
- Constraint $(1) \rightarrow (2)$ and $(1) \rightarrow (5)$ arise from the synchronizes-with relationship between thread construction and the start of the thread function [thread.thread.constr]/6. This also establishes the modification order of both
XandYvia the write-write coherence guarantees described in [intro.races]/15. - Constraint $(4) \rightarrow (5)$ and $(7) \rightarrow (2)$ are coherence-orderings that arise from the requirements in [atomics.order]/3.3. For example, $(4)$ and $(5)$ are not the same atomic read-modify-write operation, and $(4)$ reads the value stored by $(1)$, and $(1)$ precedes $(5)$ in the modification order of
Y. - From [atomics.order]/4.4,
memory_order::seq_cstfence $A$ happens-before $(4)$, and $(5)$ happens-beforememory_order::seq_cstfence $B$, therefore $(3)$ must precede $(6)$ in the single total order $S$ on allmemory_order::seq_cstoperations. By symmetric reasoning, $(6)$ must also precede $(3)$ in the same total order $S$.
This is impossible, hence a contradiction. Therefore the execution where r1 == 0 && r2 == 0 is forbidden.
Now, returning to asymmetric thread fences. The key idea is that in some concurrent algorithms, we care about optimizing a common path at the expense of an uncommon path. If we are willing to let the slow path absorb stronger synchronization costs, we can restructure the code using asymmetric fences. The paper illustrates this with the following transformation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// Globals:
atomic_int x{0}, y{0};
int r1, r2;
// Fast path:
x.store(1, memory_order_relaxed);
asymmetric_thread_fence_light(); // Like atomic_signal_fence;
// only inhibits compiler reordering
r1 = y.load(memory_order_relaxed);
// Slow path:
y.store(1, memory_order_relaxed);
asymmetric_thread_fence_heavy(); // Stronger than atomic_thread_fence(memory_order_seq_cst);
r2 = x.load(memory_order_relaxed);
// Happens after both fast path and slow path are complete.
assert(!(r1 == 0 && r2 == 0)); // Never fails.
That’s all we need to know about them for now. Let’s now move on to how these asymmetric fences are implemented.
Asymmetric Light Fence - Compiler Barrier
Let’s start with the simpler primitive: asymmetric_thread_fence_light. In Folly’s implementation, this is implemented using asm volatile("" : : : "memory") on GCC/Clang or _ReadWriteBarrier() on MSVC, with std::atomic_thread_fence(order) used as a fallback. As a side note, asm declarations are only conditionally supported in C++ according to [dcl.asm]/1, so we will refer to GCC’s documentation, specifically the extended asm section for the exact semantics here.
1
2
3
4
asm asm-qualifiers ( AssemblerTemplate
: OutputOperands
[ : InputOperands
[ : Clobbers ] ])
Here, we only care about the clobber list, specifically the special "memory" clobber argument:
The
"memory"clobber tells the compiler that the assembly code performs memory reads or writes to items other than those listed in the input and output operands (for example, accessing the memory pointed to by one of the input parameters). To ensure memory contains correct values, GCC may need to flush specific register values to memory before executing the asm. Further, the compiler does not assume that any values read from memory before an asm remain unchanged after that asm; it reloads them as needed. Using the"memory"clobber effectively forms a read/write memory barrier for the compiler.Note that this clobber does not prevent the processor from doing speculative reads past the asm statement. To prevent that, you need processor-specific fence instructions.
This means that the compiler must preserve the ordering of memory reads and writes with respect to asm volatile("" : : : "memory"), effectively making it a compiler barrier. However, this places constraints only on instruction reordering performed by the compiler, not on the processor itself. The CPU may still execute memory operations out-of-order at runtime.
As an additional note, we can also examine what the volatile qualifier does here:
GCC’s optimizers sometimes discard
asmstatements if they determine there is no need for the output variables. Also, the optimizers may move code out of loops if they believe that the code will always return the same result (i.e. none of its input values change between calls). Using thevolatilequalifier disables these optimizations.asmstatements that have no output operands andasm gotostatements, are implicitly volatile.
Here, volatile simply prevents unwanted compiler optimizations on the asm statement itself. Strictly speaking, it is not necessary in this case since an asm statement without output operands is already implicitly volatile.
Asymmetric Heavy Fence - membarrier()
The key synchronization mechanism behind asymmetric fences lies in asymmetric_thread_fence_heavy. There are several implementation strategies, but we will focus on the usual Linux path: relying on the membarrier() syscall (Another alternative is to force a TLB shootdown, though I am not familiar enough with that approach to discuss it in detail). As before, std::atomic_thread_fence(order) is used as a fallback.
Let’s take a look at the documentation:
The
membarrier()system call helps reducing the overhead of the memory barrier instructions required to order memory accesses on multi-core systems. However, this system call is heavier than a memory barrier, so using it effectively is not as simple as replacing memory barriers with this system call, but requires understanding of the details below.Use of memory barriers needs to be done taking into account that a memory barrier always needs to be either matched with its memory barrier counterparts, or that the architecture’s memory model doesn’t require the matching barriers.
There are cases where one side of the matching barriers (which we will refer to as “fast side”) is executed much more often than the other (which we will refer to as “slow side”). This is a prime target for the use of
membarrier(). The key idea is to replace, for these matching barriers, the fast-side memory barriers by simple compiler barriers, for example:asm volatile ("" : : : "memory")and replace the slow-side memory barriers by calls tomembarrier().This will add overhead to the slow side, and remove overhead from the fast side, thus resulting in an overall performance increase as long as the slow side is infrequent enough that the overhead of the
membarrier()calls does not outweigh the performance gain on the fast side.
This is exactly the asymmetric tradeoff we discussed earlier, that is replacing the fast path’s hardware fence with a compiler barrier, while shifting the heavier synchronization cost onto the infrequent slow path. The syscall signature for membarrier() is:
1
int syscall(SYS_membarrier, int cmd, unsigned int flags, int cpu_id);
For this post, we will focus primarily on the 2 specific cmd arguments used by Folly: MEMBARRIER_CMD_PRIVATE_EXPEDITED and MEMBARRIER_CMD_REGISTER_PRIVATE_EXPEDITED. Let’s have a quick look on the documentation for that:
MEMBARRIER_CMD_REGISTER_PRIVATE_EXPEDITED(since Linux 4.14) Register the process’s intent to useMEMBARRIER_CMD_PRIVATE_EXPEDITED.
This command simply registers the process’s intent to later use membarrier() with MEMBARRIER_CMD_PRIVATE_EXPEDITED.
MEMBARRIER_CMD_PRIVATE_EXPEDITED(since Linux 4.14)
Execute a memory barrier on each running thread belonging to the same process as the calling thread.Upon return from the system call, the calling thread has a guarantee that all its running thread siblings have passed through a state where all memory accesses to user-space addresses match program order between entry to and return from the system call (non-running threads are de facto in such a state). This guarantee is provided only for threads in the same process as the calling thread.
The “expedited” commands complete faster than the non-expedited ones; they never block, but have the downside of causing extra overhead.
A process must register its intent to use the private expedited command prior to using it. We choose
MEMBARRIER_CMD_PRIVATE_EXPEDITEDinstead ofMEMBARRIER_CMD_GLOBALorMEMBARRIER_CMD_GLOBAL_EXPEDITEDbecause we only require the barrier to affect threads within a single process.
The documentation also gives us the guarantee for each targeted thread, there exists some time $T$ during the interval between the invocation and return of membarrier() at which its memory accesses to user-space addresses are consistent with the program order in the emitted assembly. That is, for each targeted thread, there exists some point $T$ during that interval where no memory accesses $A$ and $B$ can exist such that $A$ is program-ordered before $B$, yet the effects of $B$ are observable before those of $A$.
Additionally, to ensure this works as intended, membarrier() enforces an ordering guarantee on the targeted threads, stated as follows:
All memory accesses performed in program order from each targeted thread are guaranteed to be ordered with respect to
membarrier().
In short, a thread’s program-order memory accesses are ordered with respect to membarrier(), thereby separating operations that occur before the barrier from those that occur after it. Within a thread, writes (and reads) deemed to have happened before the membarrier() must be globally visible (and satisfied) before writes (and reads) that are deemed to happen after the membarrier(). If you remember from my previous blog, this is basically what sync/hwsync does for PowerPC, as we will see shortly.
The Linux manual page summarizes the pairwise ordering relationships between these primitives with the following table (O: ordered, X: not ordered):
| barrier() | smp_mb() | membarrier() | |
|---|---|---|---|
| barrier() | X | X | O |
| smp_mb() | X | O | O |
| membarrier() | O | O | O |
How does Linux Membarrier work?
I’m no Linux kernel expert, and this is actually my first time poking around in Linux source code. Because of that, we won’t be doing an exhaustive deep dive, but we will look at how it is implemented under the hood and why it works. To keep things manageable, we will focus specifically on the expedited private membarrier() call used by Facebook’s Folly library, which fundamentally boils down to call_membarrier(MEMBARRIER_CMD_PRIVATE_EXPEDITED):
1
2
3
4
5
6
7
FOLLY_ERASE int call_membarrier(int cmd, unsigned int flags = 0) {
if (linux_syscall_nr_membarrier < 0) {
errno = ENOSYS;
return -1;
}
return linux_syscall(linux_syscall_nr_membarrier, cmd, flags);
}
If we trace this down into the Linux kernel source and strip away the comments and conditional branches that don’t apply to our specific arguments, we are left with the following skeleton:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
static void ipi_mb(void *info)
{
smp_mb(); /* IPIs should be serializing but paranoid. */
}
static int membarrier_private_expedited(int flags, int cpu_id)
{
cpumask_var_t tmpmask;
struct mm_struct *mm = current->mm;
smp_call_func_t ipi_func = ipi_mb;
{ // Removed other if cases
WARN_ON_ONCE(flags);
if (!(atomic_read(&mm->membarrier_state) &
MEMBARRIER_STATE_PRIVATE_EXPEDITED_READY))
return -EPERM;
}
if (flags != MEMBARRIER_FLAG_SYNC_CORE &&
(atomic_read(&mm->mm_users) == 1 || num_online_cpus() == 1))
return 0;
smp_mb(); // (1)
if (cpu_id < 0 && !zalloc_cpumask_var(&tmpmask, GFP_KERNEL))
return -ENOMEM;
SERIALIZE_IPI();
cpus_read_lock();
{
int cpu;
rcu_read_lock();
for_each_online_cpu(cpu) {
struct task_struct *p;
p = rcu_dereference(cpu_rq(cpu)->curr);
if (p && p->mm == mm)
__cpumask_set_cpu(cpu, tmpmask);
}
rcu_read_unlock();
}
{
if (flags != MEMBARRIER_FLAG_SYNC_CORE) {
preempt_disable();
smp_call_function_many(tmpmask, ipi_func, NULL, true); // (2)
preempt_enable();
}
}
if (cpu_id < 0)
free_cpumask_var(tmpmask);
cpus_read_unlock();
smp_mb(); // (3)
return 0;
}
The core execution flow of the implementation involves $(1) \rightarrow (2) \rightarrow (3)$, that simply involves smp_mb() $\rightarrow$ send inter-processor interrupts(IPI) to call smp_mb() on other cores $\rightarrow$ wait for the execution of smp_mb() on the targeted cores to complete $\rightarrow$ smp_mb(). There are 2 helpful documentation regarding this: the top-level comments in kernel/sched/membarrier.c and Documentation/scheduler/membarrier.rst. We’ll explore the main cases to see how this actually works.
Case 1: Userspace Thread Execution after Membarrier-Induced IPI
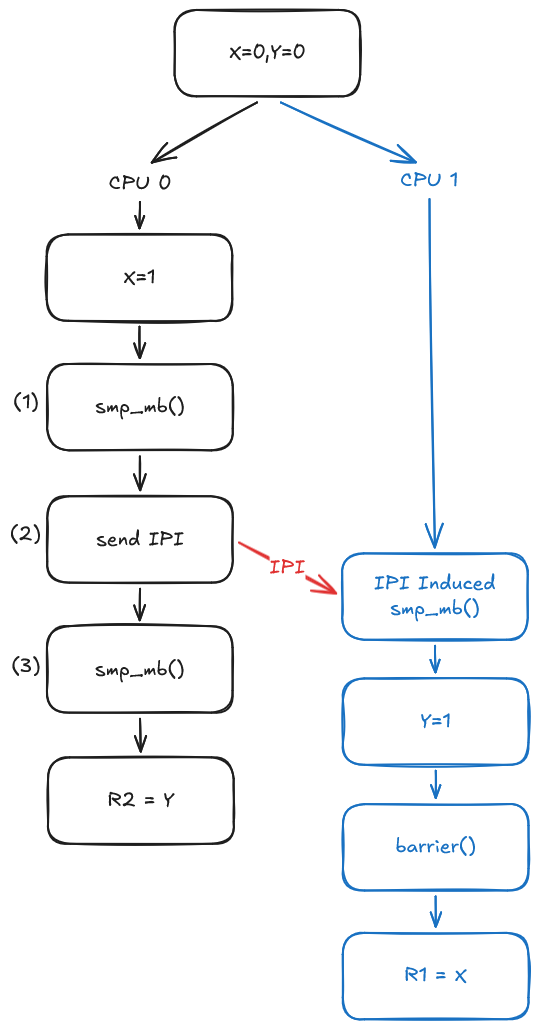
This case illustrates exactly why membarrier() must execute an smp_mb() before sending the IPI to the other cores (marked as $(1)$). To understand why, we have to look at what happens if $(1)$ is omitted. Without that first smp_mb(), the write operation x = 1 is free to be reordered until after the IPI has already been sent at $(2)$.
If that reordering happens, we run into the following scenario:
- CPU 0 sends the IPI to CPU 1.
- CPU 1 receives the IPI and executes
smp_mb(). - CPU 1 can execute the read of
r1 = xbefore the write ofy = 1becomes globally visible, asbarrier()is only a compiler barrier. As CPU 0’sx = 1is reordered after sending the IPI, CPU 1 readsr1 = 0. - Before CPU 1 writes
y = 1, CPU 0 readsr2 = y, hence readingr2 = 0.
This results in the forbidden r1 == 0 && r2 == 0 outcome, entirely breaking the guarantees of membarrier(). By enforcing smp_mb() at $(1)$, the kernel creates a a strict ordering chain, similar to a fence-fence synchronization of std::atomic_thread_fence:
smp_mb() on CPU 0 $\rightarrow$ Send IPI $\rightarrow$ Receive IPI on CPU 1 $\rightarrow$ smp_mb() on CPU 1. (Note: The Send IPI $\rightarrow$ Receive IPI sequence does not itself establish memory ordering guarantees. Because IPIs are hardware signaling mechanisms and do not interact with shared memory, they are not considered events under the Linux Kernel Memory Consistency Model (LKMM). However, it is helpful as an intuitive abstraction to understand the core idea).
This chain effectively establishes a happens-before relationship between memory operations preceding the smp_mb() at $(1)$ on the sending CPU and memory operations following the IPI-induced barrier on the receiving CPU. Because both sides use smp_mb(), this ordering is globally respected by all CPUs.
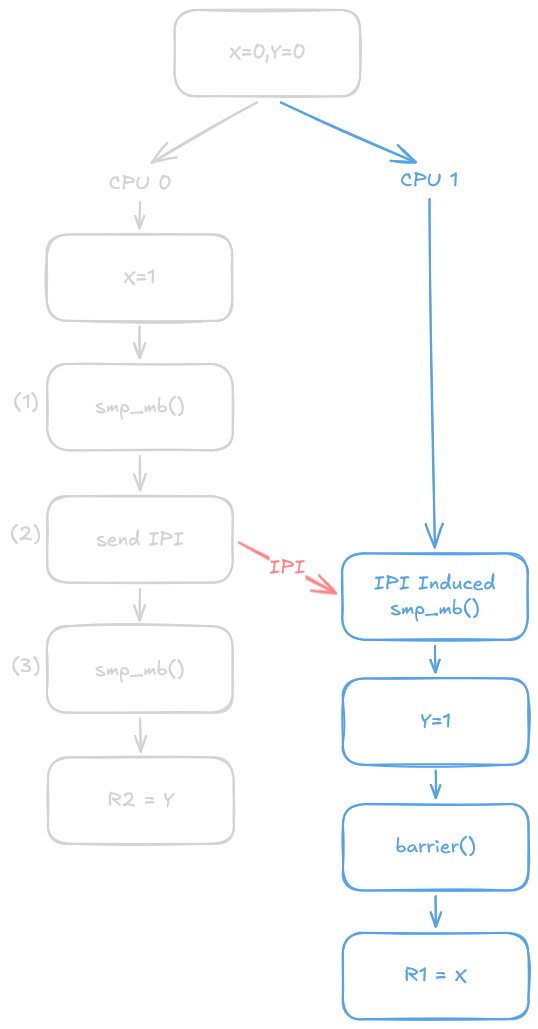
Case 2: Userspace Thread Execution before Membarrier-Induced IPI
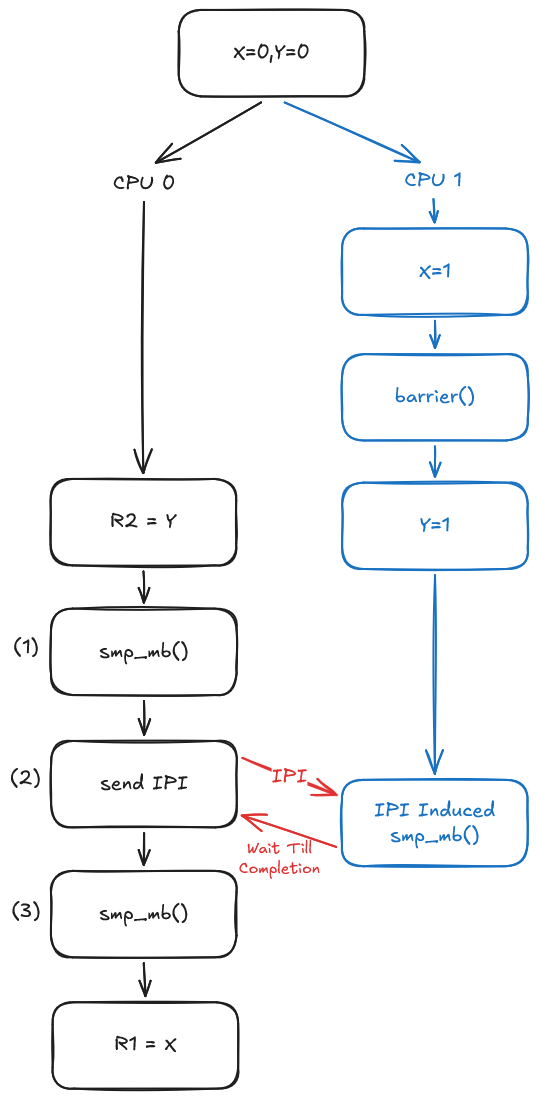
This case, on the other hand, shows why membarrier() must execute an smp_mb() after sending the IPI to the other cores (marked as $(3)$). Once again, let’s look at what happens if $(3)$ is omitted. Without that second smp_mb(), the read operation r1 = x is free to be reordered before the IPI has been sent at $(2)$.
If that reordering happens, we run into the following scenario:
- CPU 1 can make the write to
y = 1visible before the write tox = 1. Even thoughbarrier()prevents the compiler from reordering these statements, it provides no hardware memory ordering, meaning the CPU architecture itself is free to allow the writes to become visible in a different order. - CPU 0 reads
r2 = 1. - As CPU 0’s
r1 = xis reordered to before sending the IPI, CPU 0 readsr1 = 0. - CPU 0 sends the IPI to CPU 1, which then executes the IPI-induced
smp_mb().
This results in the r1 == 0 && r2 == 1 scenario, which is not allowed to happen under the guarantees provided by membarrier(). Again with smp_mb() at $(3)$, the kernel enforces this particular chain of events: Receive IPI on CPU 1 $\rightarrow$ smp_mb() on CPU 1 $\rightarrow$ CPU 0 waits for CPU 1 to finish executing the barrier $\rightarrow$ smp_mb() on CPU 0. This chain effectively establishes a happens-before relationship between memory operations preceding the IPI-induced barrier on the receiving CPU and memory operations following the smp_mb() at $(3)$ on the sending CPU. Because both sides use smp_mb(), all CPUs must observe these operations as being ordered in that direction.
Case 3: Context Switching - Scheduling Userspace Thread $\rightarrow$ Kthread $\rightarrow$ Userspace Thread
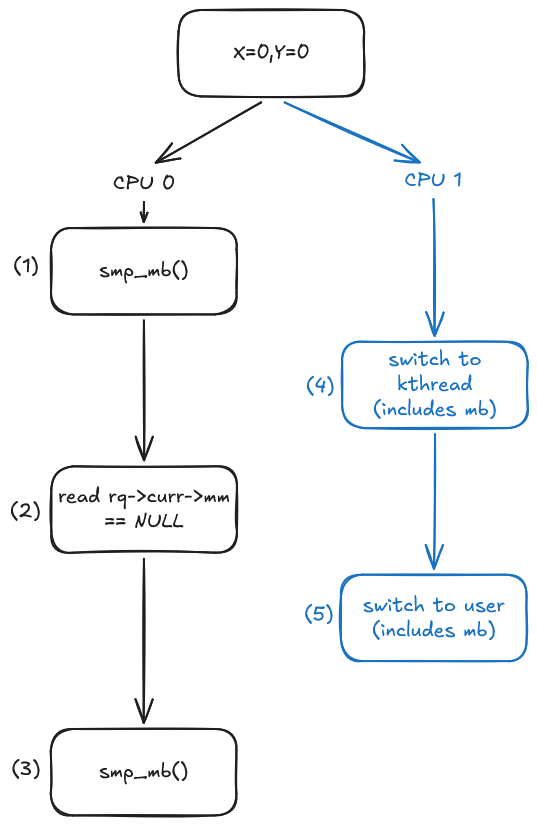
Note that in $(4)$, switching to a kernel thread involves an execution path of rq_lock(rq, &rf) $\rightarrow$ smp_mb__after_spinlock(), which effectively acts as an smp_mb(), followed by a write to RCU_INIT_POINTER(rq->curr, next) inside __schedule(int sched_mode). In our scenario, this update is later observed by the membarrier call at $(2)$. This sequence establishes a read-from relationship in the execution graph, as visualized below. Together with the memory barriers at $(3)$ and $(4)$, this establishes a global ordering between the memory operations preceding $(4)$ and those following $(3)$.
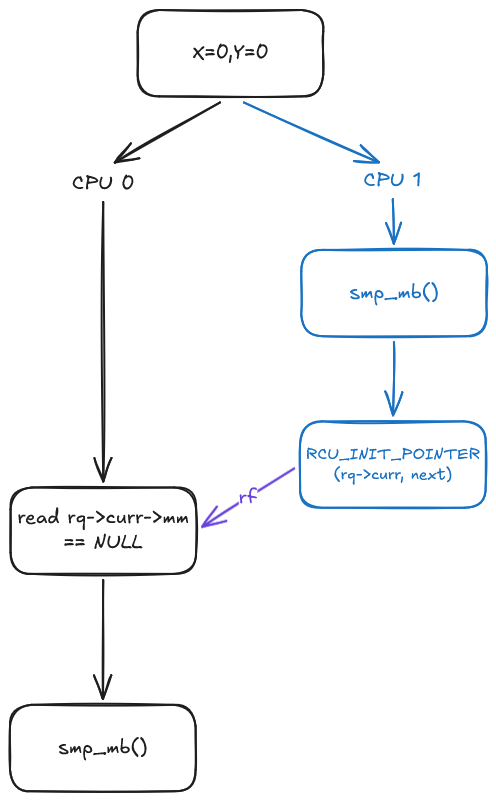
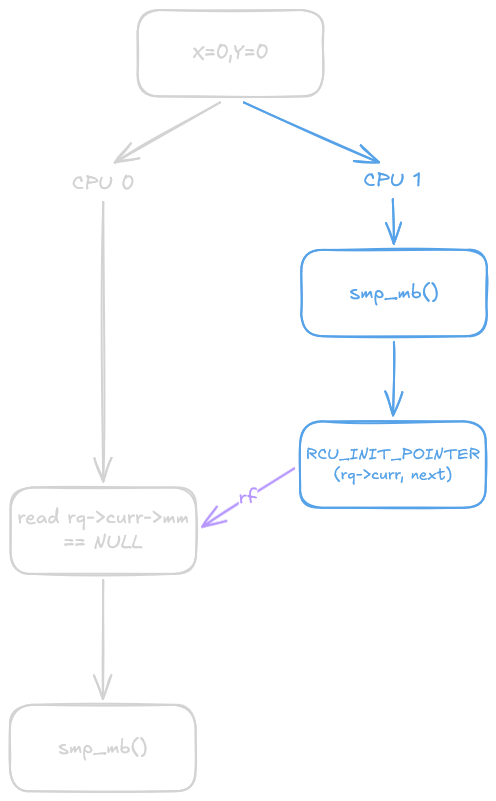
For the final key to the puzzle, let’s observe how the memory barriers at $(1)$ and $(5)$ relate to one another. As documented in membarrier.rst, this smp_mb() may appear in different locations depending on architecture, but it always occurs after rq->curr is updated in context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next, struct rq_flags *rf) call. At first glance, nothing seems to explicitly link these two memory barriers together. However, because the membarrier() call at $(2)$ observes the previous value of rq->curr, while the remote core’s transition back to userspace subsequently writes a new value to the same location, we obtain a read-before edge in the execution graph (a concept detailed in my previous blog post on strongly happens before relationships).
The execution graph below illustrates this ordering: 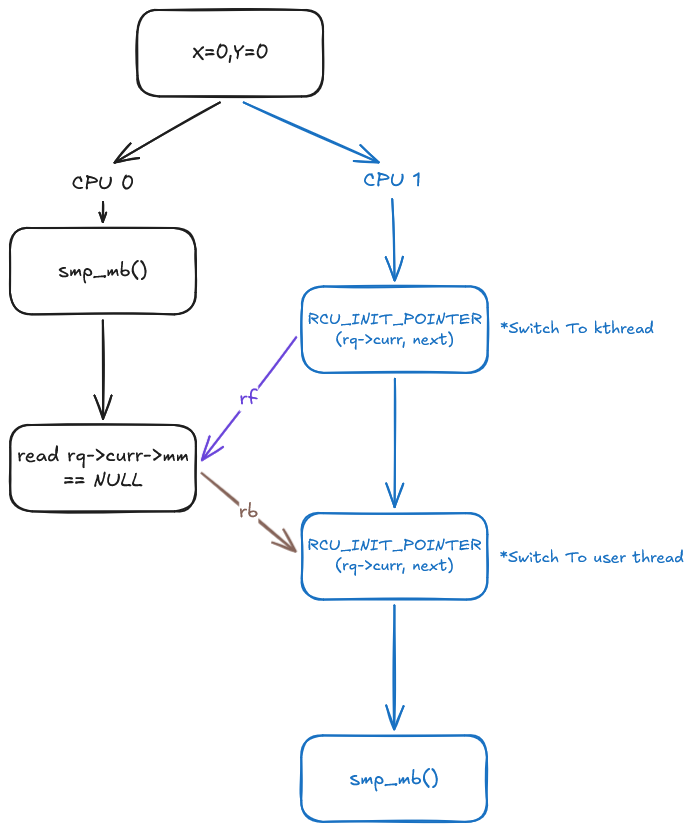
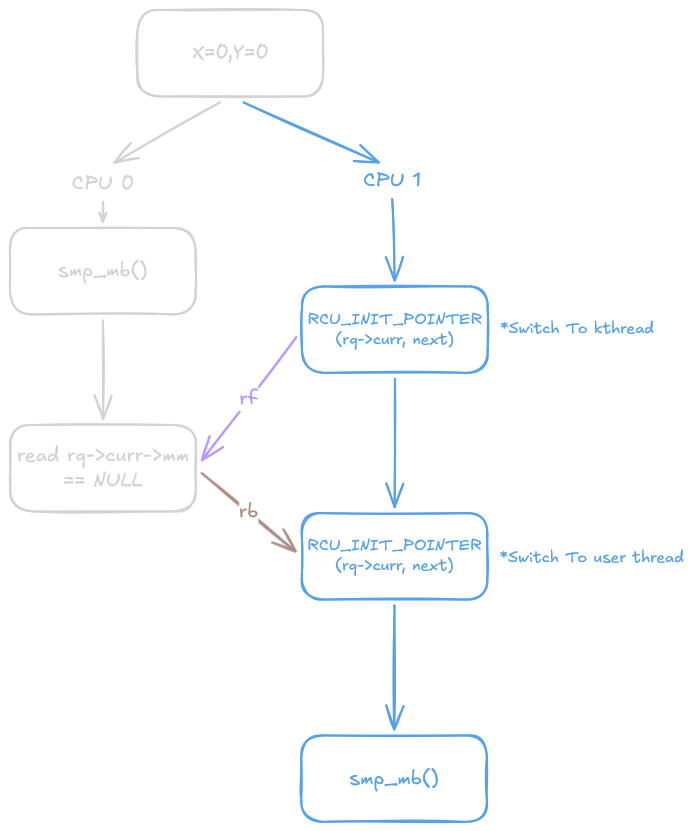
Why does this give us the guarantee we need? This is analogous to our Dekker’s example: 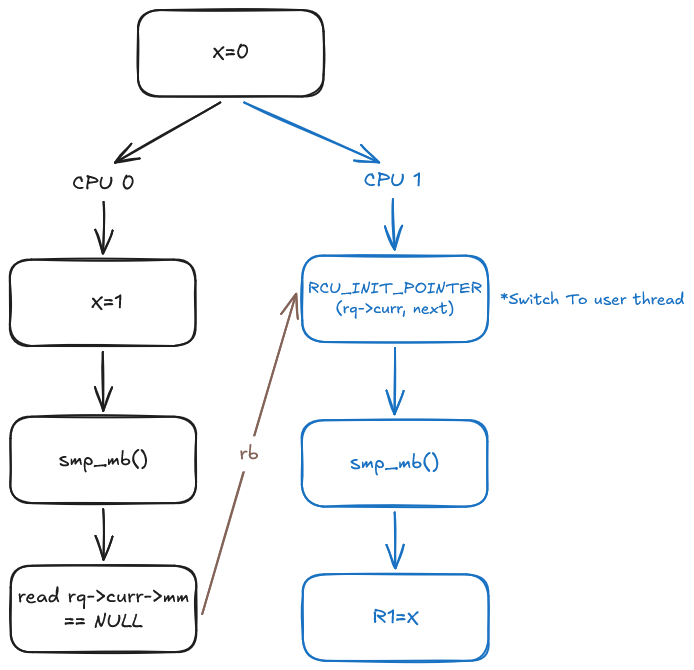
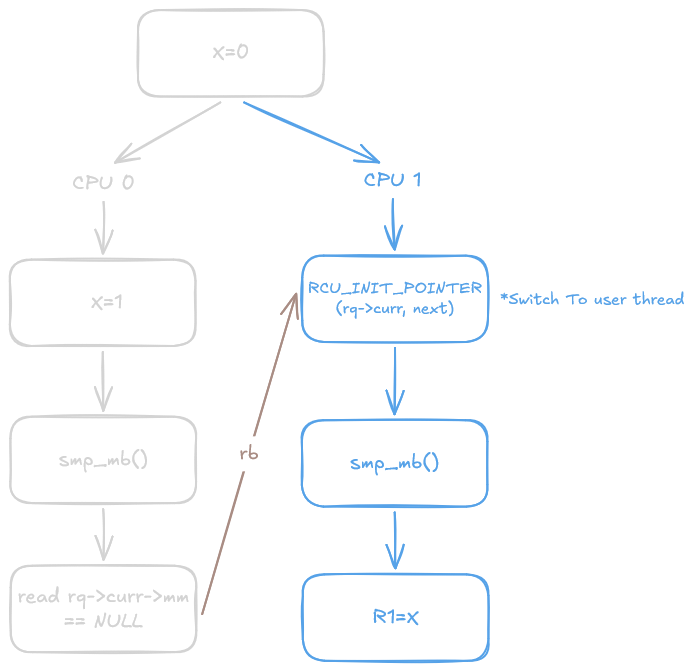
Using this example, if r1 = x reads the value 0, this forms a second read-before edge, completing a cycle in the execution graph. This is explicitly disallowed by LKMM as it is a violation of the acyclic property of the propagates-before relation (and similarly violates the single total order $S$ on all memory_order::seq_cst operations in the C++ memory model). Consequently, memory accesses after $(5)$ are ordered after those preceding $(1)$, preventing the forbidden execution. However, do note that a read-before edge does not constitute a happens-before and later I will highlight the difference this causes.
With that, we have walked through the primary execution paths to understand exactly how membarrier() enforces consistency under the hood (though additional cases exist within the long-form comments of kernel/sched/membarrier.c).
Sidenote: Details for Readers
Although we have covered the core execution flow of membarrier(), I want to highlight a few extra details for readers interested in the exact kernel mechanics.
The Memory Ordering Gurantees of IPIs
As we established earlier, IPIs themselves are hardware signals that do not interact with shared memory, meaning LKMM does not treat them as ordering events. So, what actually establishes the formal synchronization edges in our execution graph?
The answer lies in the SMP callback queue infrastructure. When we say membarrier() sends an IPI to force another CPU to execute smp_mb(), internally it relies on smp_call_function_many_cond(const struct cpumask *mask, smp_call_func_t func, void *info, unsigned int scf_flags, smp_cond_func_t cond_func). Before the IPI is issued, this function packages the smp_mb() callback into a call_single_data(csd) object and enqueues it onto the target CPU’s call_single_queue in shared memory. When the remote CPU receives the IPI, its interrupt handler executes __flush_smp_call_function_queue(bool warn_cpu_offline). This function reads the newly enqueued callback from shared memory, establishing a read-from relationship between the producer CPU (which enqueued the csd) and the consumer CPU (which executes it). For the return path, when the membarrier() caller waits for completion, it calls csd_lock_wait(csd), which blocks until the remote CPU signals completion via csd_unlock(csd). This introduces a read-from relationship through the completion state.
The final piece of the puzzle is this: if sending an IPI does not inherently involve shared memory, how do we guarantee the interrupted core actually observes the newly enqueued csd object after it is interrupted? The kernel solves this using architecture-specific memory barriers immediately before the IPI is issued. On x86-64 x2APIC mode, a combination of mfence; lfence is used, as stated in the Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3 13.12.3:
A
WRMSRto an APIC register may complete before all preceding stores are globally visible; software can prevent this by inserting a serializing instruction or the sequenceMFENCE;LFENCEbefore theWRMSR. (Note: I have not found formal documentation explaining this mechanism in detail. The closest available explanation appears in the Linux Kernel comment inweak_wrmsr_fence, which states:MFENCEmakes writes visible, but only affects load/store instructions.WRMSRis unfortunately not a load/store instruction and is unaffected byMFENCE. TheLFENCEensures that theWRMSRis not reordered.)
On ARM64, the kernel uses dsb(ishst), which ensures that all stores occurring before the DSB have completed globally before the DSB instruction itself completes.
In both cases, these barriers ensure that the newly enqueued csd is globally visible in memory before the remote core can observe and act upon the interrupt.
Fast Path for membarrier()
membarrier() actually has a fast path. If atomic_read(&mm->mm_users) == 1 || num_online_cpus() == 1, the kernel simply skips the remaining membarrier() logic. Assuming no CPU hotplugging, the single-CPU optimization is incredibly straightforward. A CPU hardware pipeline has no concept of software threads or OS context switches and merely executes an instruction stream. While instructions may be reordered internally, the architecture guarantees that execution behaves exactly as if that stream were processed sequentially. Consequently, on a single-core machine, context-switching between threads on the same physical processor cannot create the cross-CPU memory visibility issues that membarrier() is designed to prevent, making global memory barrier synchronization entirely unnecessary.
For the other case, mm_users == 1 indicates that the current task is the only task using this address space. In this situation, no other tasks share the same address space and therefore no other execution context exists that could concurrently observe memory effects from another CPU. As a result, the cross-CPU ordering guarantees provided by membarrier() are unnecessary.
Quick Note on smp_mb()
smp_mb() is simply a full memory barrier and its underlying implementation is architecture-dependent. For example, it uses dmb(ish) for ARM64, sync for PowerPC, asm volatile("lock addl $0,-4(%rsp)" ::: "memory", "cc") for x86-64 etc. (For those curious why not an mfence, you can read the reasoning in this Linux kernel commit).
Other Minor Implementation Details
A few final details worth noting before we wrap up this section:
- There is a
SERIALIZE_IPI()call before checking each CPU core. ThisSERIALIZE_IPI()call simply acquiresmembarrier_ipi_mutexand prevent hammeringmembarrier()calls, which could otherwise saturate the machine with interrupts. - There is also a
cpus_read_lock()andcpus_read_unlock()call withinmembarrier(). This is related to CPU hotplugging, which falls outside the scope of this post, though I highly encourage interested readers to look into it and comment on the details below.
Formalization for C++ Standard
The final problem is establishing inter-thread synchronization and memory ordering constraints between asymmetric_thread_fence_light and asymmetric_thread_fence_heavy. Let’s take a look at the original proposal and the criteria used to evaluate the formalization of these ideas:
- Asymmetric fences should be no stronger than the semantics provided by the underlying implementation.
- Asymmetric fences should be implementable on platforms that lack underlying OS support, with a cost no more (or at least, not much more) than a plain fence.
We’ll take a look at the failed attempts mentioned in the paper, followed by the current formalization.
The Straightforward Idea
The first approach is as follows:
- Heavy fences are also
memory_order_seq_cstfences.- For every light fence $L$ and heavy fence $H$, either $H$ synchronizes with $L$ or $L$ synchronizes with $H$.
This formalization seems relatively straightforward, and we can see why it works for Dekker’s example using a derivation similar to the one shown above. Unfortunately, as David Goldblatt mentioned in the proposal, it does not actually work. Let’s take a look at the counter-example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// Globals:
atomic_int x{0}, y{0}, z{0};
int r1, r2, r3;
// T0
x.store(1, memory_order_relaxed);
asymmetric_thread_fence_light();
r1 = y.load(memory_order_relaxed);
// T1
y.store(1, memory_order_relaxed);
asymmetric_thread_fence_heavy();
r2 = z.load(memory_order_relaxed);
// T2
z.store(1, memory_order_relaxed);
asymmetric_thread_fence_light();
r3 = x.load(memory_order_relaxed);
assert(!(r1 == 0 && r2 == 0 && r3 == 0));
Unfortunately, this assert can indeed fire. Below is the execution graph showing how this outcome could occur.
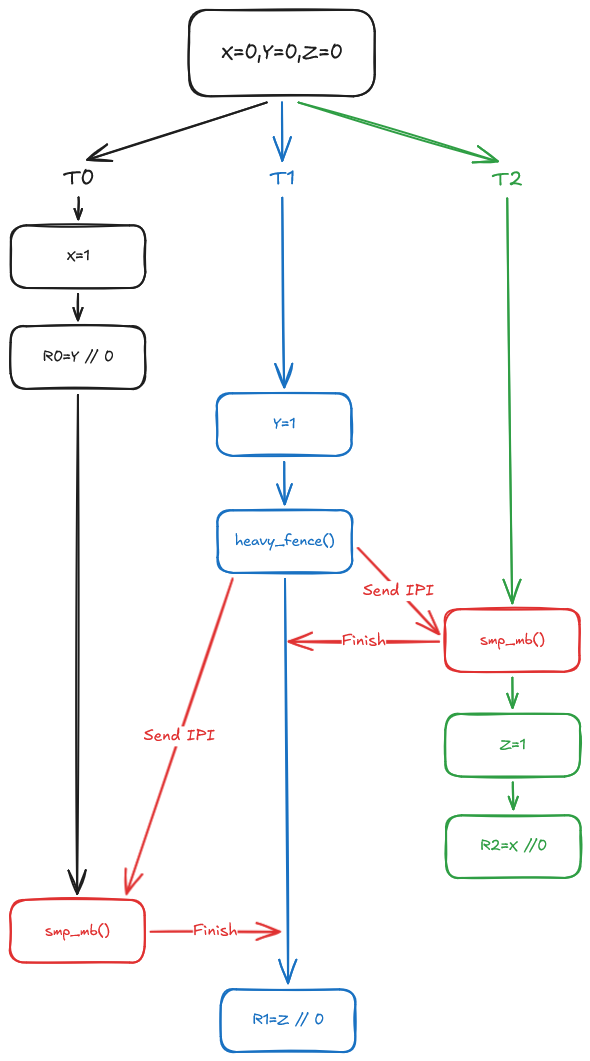
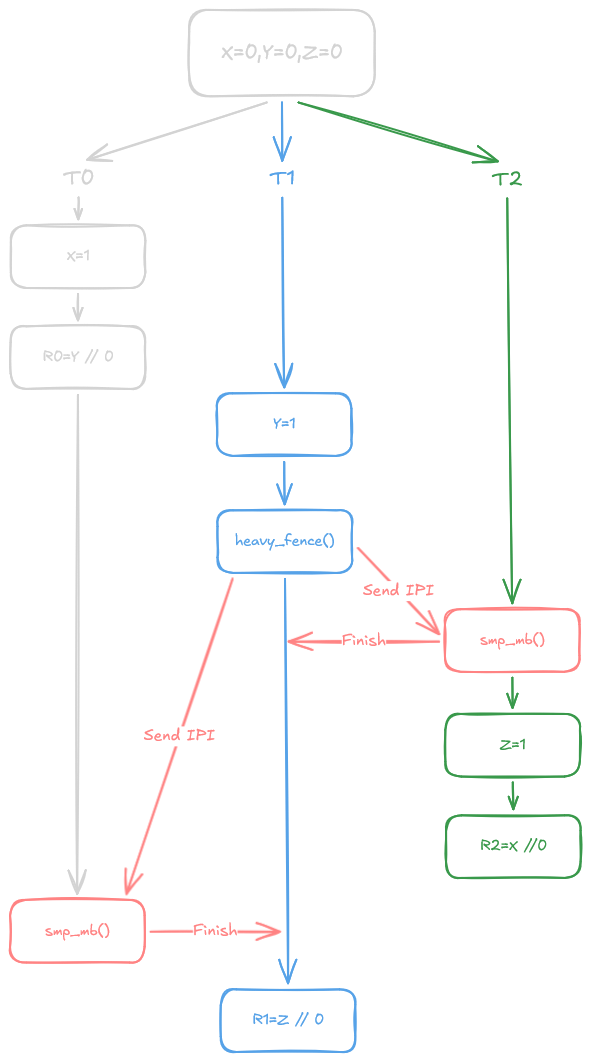
The problem now is that using synchronizes-with actually forbids that outcome. David explains it well it his proposal:
R0 == 0would imply that T0’s light fence synchronizes with T1’s heavy fence. Similarly,R1 == 0implies that T1’s heavy fence synchronizes with T2’s light fence. Combining these, we would have that T0’s store toXshould happen before T2’s load, and that thereforeR2 == 1.
From [intro.races]/9 and [intro.races]/10, we know that the synchronizes-with relationship implies a happens-before relationship, and that the happens-before relationship is transitive. As this formalization mathematically forbids an outcome that the underlying hardware actually allows, it would force implementations to emit stronger, more expensive barriers to prevent it. This transitivity is ultimately what caused this formalization to fail criterion 1.
Preventing Transitivity
In an attempt to prevent the transitivity issue, the proposal’s second attempt replaces the previous rule with the following:
For every light fence $L$ and heavy fence $H$, one of the following holds:
a. Every evaluation that is sequenced before $L$ strongly happens before every evaluation that $H$ is sequenced before.
b. Every evaluation that is sequenced before $H$ strongly happens before every evaluation that $L$ is sequenced before.
To see how this breaks the transitivity chain, let’s refer to the execution graph below: 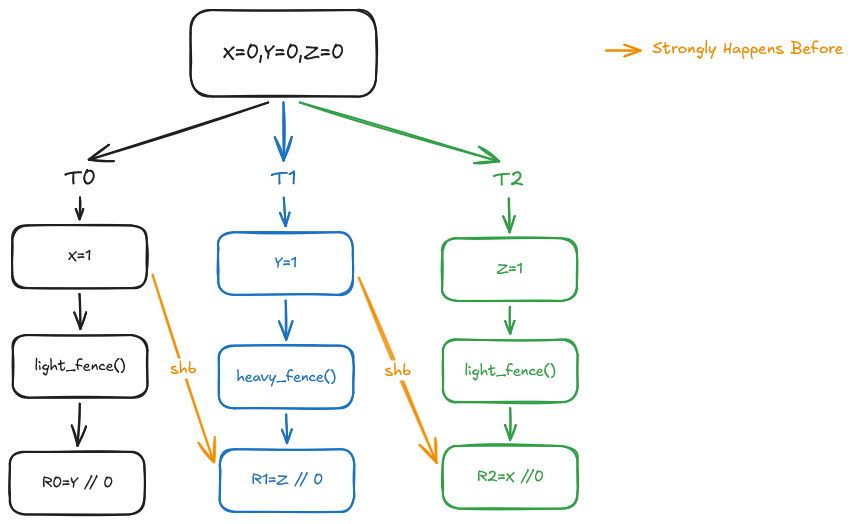
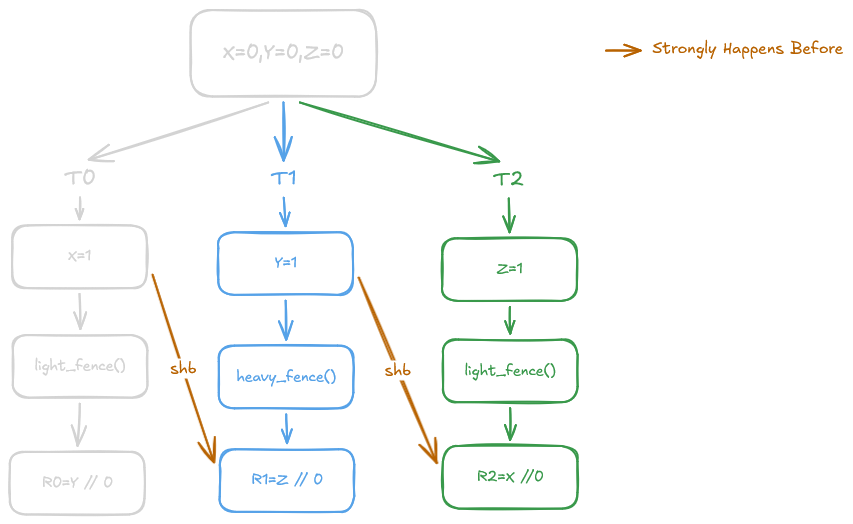
Notice that there is no relationship forced between X = 1 and R2 = X, successfully achieving the decoupling we require. Unfortunately, this approach fails Criterion 2. To understand why, consider the following example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// Globals
int data{0};
atomic_int x{0};
atomic_bool P0_won_the_race{false};
// P0
data = 0x123456;
fence0();
if (x.load(std::memory_order_relaxed) == 0) {
P0_won_the_race.store(true, std::memory_order_relaxed);
}
// P1
x.store(1, std::memory_order_relaxed);
fence1();
if (P0_won_the_race.load(std::memory_order_relaxed)) {
assert(data == 0x123456);
}
Let’s evaluate what happens if both fence0() and fence1() are implemented using standard std::atomic_thread_fence(std::memory_order_seq_cst). According to [intro.races]/21:
Two actions are potentially concurrent if
- they are performed by different threads, or
- they are unsequenced, at least one is performed by a signal handler, and they are not both performed by the same signal handler invocation. The execution of a program contains a data race if it contains two potentially concurrent conflicting actions, at least one of which is not atomic, and neither happens before the other, except for the special case for signal handlers described below. Any such data race results in undefined behavior.
As David highlights in the proposal:
The sequentially consistent portions of the fence rules only place restrictions on the coherence orders of affected object, not establish happens-before relationships between accesses. (at least, not ones that an
memory_order_acq_relfence wouldn’t, given the same observed values).
As the fences fail to establish a happens-before relationship between the non-atomic write (data = 0x123456) and the non-atomic read (assert(data == 0x123456)), this execution is considered UB under the C++ standard, meaning the assert is legally allowed to fire.
Now, let’s look at what happens if we replace fence0() and fence1() with our new asymmetric fences under the proposed wording. The new rule explicitly dictates that either:
data = 0x123456strongly happens beforeassert(data == 0x123456), orx.store(1, std::memory_order_relaxed)strongly happens beforex.load(std::memory_order_relaxed).
By forcing this explicit happens-before edge, the new formalization mathematically prevents the data-race, which, ironically, ends up being the issue. Since this new wording provides stronger guarantees than plain memory_order_seq_cst fences, asymmetric fences cannot use standard fences as a fallback implementation on unsupported platforms, which fundamentally violates criterion 2.
On an interesting side note, I would argue that this proposed formalization also violates criterion 1 (implementability with membarrier()). If we recall Cases 1 and 2 from our earlier analysis, the implementation establishes a happens-before relationship between the relevant operations. In contrast, Case 3 partially derives its ordering from a read-before relationship. While this is sufficient to satisfy the specific ordering guarantees of the membarrier() API, a read-before relationship does not itself establish a happens-before relationship under the C++ memory model (nor LKMM), even with smp_mb().
As a consequence, ordinary loads and stores remain unordered and may therefore race. To prove this, I constructed the following litmus test using herd7 and the LKMM specifications (found under tools/memory-model in the Linux kernel):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
C membarrier_pre_switch_race
{}
P0(int *data, int *x, int *P0_won_the_race, int *rq_state)
{
// Plain write to data payload
*data = 1; // TEST: race condition case
// WRITE_ONCE(*data, 1); // TEST: No race condition case
// ====================================================
// fence0(): sys_membarrier() path on CPU0
// ====================================================
smp_mb(); // (1) entry barrier
int r_rq = READ_ONCE(*rq_state); // (2) read rq->curr->mm == NULL
smp_mb(); // (3) exit barrier
// ====================================================
// if (x.load(relaxed) == 0)
int r0 = READ_ONCE(*x);
if (r0 == 0) {
WRITE_ONCE(*P0_won_the_race, 1);
}
}
P1(int *data, int *x, int *P0_won_the_race, int *rq_state)
{
// ====================================================
// Context switch happens at the VERY BEGINNING of P1
// ====================================================
smp_mb(); // rq_lock(); smp_mb__after_spinlock() in __schedule()
WRITE_ONCE(*rq_state, 1); // (4) switch to kthread (simulate setting rq->curr->mm = NULL)
smp_mb(); // inherent barrier in context_switch()
smp_mb(); // rq_lock(); smp_mb__after_spinlock() in __schedule()
WRITE_ONCE(*rq_state, 2); // (5) switch back to user thread (simulate setting rq->curr->mm != NULL)
smp_mb(); // inherent barrier in context_switch()
// ====================================================
// x.store(1, relaxed);
WRITE_ONCE(*x, 1);
// fence1(): Pure Compiler Barrier
barrier();
// if (P0_won_the_race.load(relaxed))
int r1 = READ_ONCE(*P0_won_the_race);
if (r1 == 1) {
int r2 = *data; // TEST: race condition case
// int r2 = READ_ONCE(*data); // TEST: No race condition case
}
}
// Can P1 confirm P0 won the race (r1 == 1) but see stale data (r2 == 0)?
// If r_rq is not 1, it will send out IPIs
filter (0:r_rq = 1)
exists (1:r1 = 1 /\ 1:r2 = 0)
Unfortunately, the built-in data-race flag is evaluated independently of the litmus test’s filter and exists clauses, making it difficult to determine whether the specific execution we are interested in is the one containing the race. Fortunately, LKMM allows us to inspect the race relation directly.
To do so, add the following lines to linux-kernel.cat (located under tools/memory-model/, use this directory as your working directory):
1
2
let race = (ww-race | wr-race | rw-race)
show race
Now run:
1
herd7 -conf linux-kernel.cfg -show cond -o . membarrier_case_3_data_race.litmus
The generated .dot file will now include edges belonging to the race relation. For this litmus test, the output contains:
1
2
3
4
5
eiid0 [label="a: W[data]=1", shape="none", fontsize=8, pos="1.000000,10.125000!", fixedsize="false", height="0.111111", width="1.000000"];
...
eiid8 [label="i: R[data]=0", shape="none", fontsize=8, pos="3.000000,0.000000!", fixedsize="false", height="0.111111", width="1.000000"];
...
eiid8 -> eiid0 [label="race", color="brown", fontcolor="brown", fontsize=8, arrowsize="0.800000"];
The edge labeled race connects the plain read of data to the plain write of data, confirming that these accesses form a data-race in the simulated membarrier() sequence!
Replacing the plain accesses to data with WRITE_ONCE() and READ_ONCE() removes the race, demonstrating that the ordering derived from the Case 3 path is insufficient to establish the happens-before relationship required to safely synchronize ordinary loads and stores. Since the proposed C++ wording requires that, for every pair of light and heavy fences, either all evaluations sequenced before the light fence strongly happens before all evaluations sequenced before the heavy fence, or vice versa, it requires a level of ordering that cannot be established by membarrier() in the Case 3 execution path. Therefore, it is not directly implementable using the system call, as the syscall is inherently incapable of providing the required semantics.
I had an incredibly insightful discussion with David regarding this behavior (and other things in the proposal), here is his response regarding this analysis:
Hmmm, this analysis seems right to me (or at least, right-looking enough that I now lack confidence in the P1202 claim is correct). I think I had convinced myself that either:
- We do the RCU-like pathway (non-expedited, strong synchronization), or
- We do IPIs (expedited, strong synchronization)
and it didn’t occur to me that there might be this sort of “skipping” mechanism where you can tell that some core won’t need the IPI (at least, without some other at-least-as-strong-as a lock on a per-core mutex or something).
I’m curious if that sort of weak ordering is really intended by the syscall semantics though – after all, the kernel doesn’t know which of the operations in userland are atomics and which are not, so it needs to promise synchronization at least as strong as necessary for any load/store.
Whether this behavior is actually intended by the syscall semantics is an interesting question in its own right. I definitely have my own opinions on the matter, but I’ll leave that up to you. Let’s discuss it down in the comments! :D
The Current Wording
The formally accepted wording includes quite a few changes, but I will highlight the main ones here. For std::memory_order_seq_cst asymmetric fences, 2 important bullets were added to [atomics.order]/4:
- if a
memory_order::seq_cstlightweight-fence $X$ happens before $A$ and $B$ happens before amemory_order::seq_cstheavyweight-fence $Y$, then $X$ precedes $Y$ in $S$; and- if a
memory_order::seq_cstheavyweight-fence $X$ happens before $A$ and $B$ happens before amemory_order::seq_cstlightweight-fence $Y$, then $X$ precedes $Y$ in $S$.
This solves both of our previous problems! The relationship is no longer transitive, and it only affects the single total order $S$ on all memory_order::seq_cst operations.
The wording also includes a section for asymmetric fences that use release-acquire semantics:
If there are evaluations $A$ and $B$, and atomic operations $X$ and $Y$, both operating on some atomic object $M$, such that $A$ is sequenced before $X$, $X$ modifies $M$, $Y$ is sequenced before $B$, and $Y$ reads the value written by $X$ or a value written by any side effect in the hypothetical release sequence $X$ would head if it were a release operation, and one of the following hold:
- $A$ is a release lightweight-fence and $B$ is an acquire heavyweight-fence; or
- $A$ is a release heavyweight-fence and $B$ is an acquire lightweight-fence then any evaluation sequenced before $A$ strongly happens before any evaluation that $B$ is sequenced before.
Technically, this wording still requires a bit of ironing out. Under the current definitions in [intro.races]/11 and [intro.races]/12, strongly happens before actually does not imply happens before for this specific asymmetric fence case. This leads to unexpected outcomes that one would normally expect from standard release-acquire semantics. This disconnect happens largely because most of the C++ standard relies on the happens before relationship to define memory ordering and coherency constraints (e.g., [intro.races]/18). I also checked with David about this discrepancy, and he shared this bit of insider context:
When SG1 added strongly happens before, we meant for it to get included into happens before, but forgot to actually include words to that effect. We talked a little bit about this at the Croyden meeting and said we needed to file a Core issue about it, but no one has actually gotten around to doing so. (This shows up in other places in the library clause too, so it’s probably something we should fix in the definitions). Thanks.
It looks like we’ll just have to wait and see what changes the committee makes in the future!
Conclusion
Well, that’s it for this post! It took over three months of deep-diving, researching, and writing to put all of this together, so I truly hope you enjoyed it and stick around for more. A massive thank you to David Goldblatt for responding to my inquiries! Getting his direct insights on the formalization was incredibly helpful and deeply appreciated.
Till next time!
Resources
- Proposal P1202R0
- Proposal P1202R5
- Working Draft, Extensions to C++ for Concurrency Version 2
- Herding Cats: Modelling, Simulation, Testing, and Data Mining for Weak Memory
- Linux Kernel Memory Consistency Model Explanation
- MEMBARRIER_CMD_{PRIVATE,GLOBAL}_EXPEDITED - Architecture requirements
- Working Draft, Standard for Programming Language C++ (C++23)
- ARM Compiler toolchain Assembler Reference
- Intel® 64 and IA-32 Architectures Software Developer Manuals
- GNU Compiler Documentation on Extended Asm
- Repairing Sequential Consistency in C/C++11
- Answer to “Why memory reordering is not a problem on single core/processor machines?”
- Memory barrier Wikipedia
- Extra Reading: The Memory Descriptor
- Extra Reading: Active MM
- Extra Reading: Static Calls in Linux
- Extra Reading: On The Fence With Dependencies
- Extra Reading: Answer to “Behavior of mprotect with multiple threads”